
随着大数据等技术的普遍应用,越来越多的技术得到普及,其中t-SNE是广泛应用于高位数据可视化的算法。t-SNE表示t-分布 随机邻域嵌入,要想了解它的原理,我们要先清楚一个概念——降维。
1D、2D和3D数据能够可视化。在数据科学领域,并不总是可以使用小于或等于3维的数据集。我们最终可能会遇到使用更高维数据的情况。对于数据科学专业人员来说,有必要可视化并了解工作数据,以更好地完成工作。为了减轻这种情况,已经发展了降维技术。
降维技术的另一个最流行的用例是在训练ML模型时降低计算复杂性。通过使用维数约简技术,数据集在大小方面被约简,同时,关于原始数据的信息被执行到低维数据。因此,机器学习算法从输入数据集中学习是简单而不耗时的。
主成分分析(PCA)是降维领域的一个巨人。它最早由Pearson于2001年开发,许多人对它进行了即兴创作。尽管PCA是一种广泛使用的技术,但它也有一些缺点,PCA的主要缺点是它将无法维护数据集的局部结构。为了缓解这个问题,t-SNE应运而生。
什么是t-SNE?
t-SNE的主要用途是可视化和探索高维数据。它由Laurens van der Maatens和Geoffrey Hinton开发和出版。t-SNE的主要目标是将多维数据集转换为低维数据集。这是最好的降维技术之一,特别是对于数据的可视化。如果我们将t-SNE应用于n维数据,它将智能地将n维数据映射到3d甚至2d数据,并且与原始数据具有非常好的相对相似性。
与PCA一样,t-SNE不是一种线性降维技术,它遵循非线性,这是它能够捕获高维数据的复杂流形结构的主要原因。
t-SNE工作原理
首先,它将通过拾取随机数据点并计算与其他数据点的欧氏距离(|x)来创建概率分布ᵢ — x(x)ⱼ|). 与所选数据点相邻的数据点将获得更多的相似性值,而远离所选数据点将获得较少的相似性。使用相似性值,它将为每个数据点创建相似性矩阵(S1)。
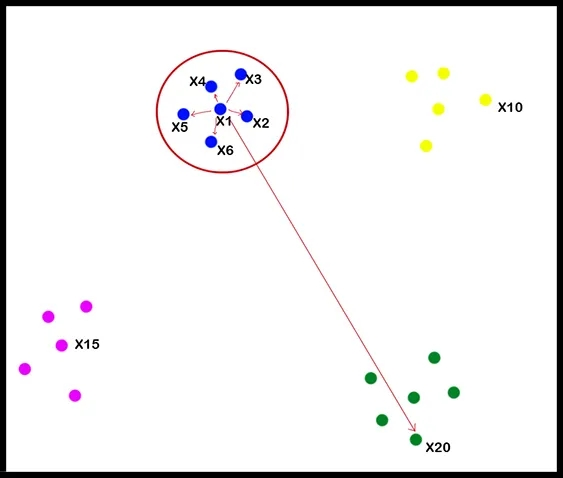
尽管不可能可视化具有3个以上维度的数据集,但仅假设上图是多维数据的可视化表示,以供示例使用。
注:术语邻居是指最接近每个点的点集。
通过上面的图像,我们可以说X1 N(X1)的邻域={X2、X3、X4、X5、X6},这意味着X2、X1、X5和X6是X1的邻居。并且在相似矩阵“S1”中获得更高的值。这是通过计算与其他数据点的欧氏距离来计算的。
另一方面,X20远离X1。因此,它将在S1中获得较低的值。
其次,根据正态分布将计算的相似距离转换为联合概率。
现在,t-SNE在所需的低维上随机排列所有数据点。

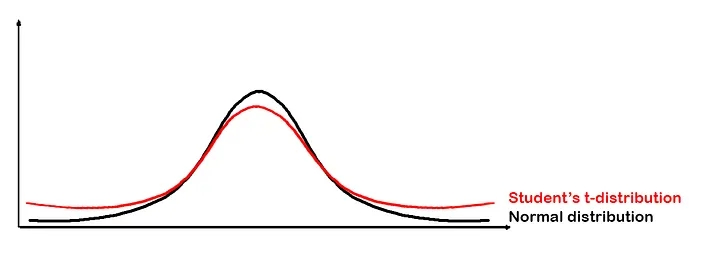
t-SNE将再次对随机排列的低维数据点进行与它对高维数据点所做的相同的计算。但在这一步中,它根据t分布分配概率。这就是t-SNE这个名字的原因。
t-SNE中的t-分布的目的是减少拥挤问题。
注:记住,对于高维数据,算法根据正态分布分配概率。
注:t分布→ 从视觉上看,t-分布很像正态分布,但通常具有更厚的尾部,这意味着数据的可变性更高。
对于低维数据点,它也将创建相似矩阵(S2)。
现在,该算法将S1与S2进行比较,并通过处理一些复杂的数学来区分S1和S2。
运行梯度下降算法,将两个分布之间的Kullback-Leibler发散(KL发散)作为代价函数。
这种KL发散有助于t-SNE通过最小化关于数据点位置的两个分布之间的值来保持数据的局部结构。
注:在统计学中,Kullback–Leibler散度是一种度量一个概率分布与另一个分布之间差异的方法。梯度下降是一种优化算法,用于最小化各种机器学习算法中的代价函数。
最后,该算法能够得到与原始高维数据具有良好相对相似性的低维数据点。
推荐大家参加中培IT学院的大数据挖掘、可视化与ChatGPT职场赋能培训课程,在课程中您将更直观地了解t-SNE工作原理并掌握其基于Python的实现。
t-SNE算法需要考虑的事项:
t-SNE算法具有扩展稠密聚类和收缩稀疏聚类的习惯。
t-SNE不保留簇之间的距离。
t-SNE是一种不确定性或随机算法,这就是为什么它的结果在每次运行中都会有轻微的变化。
尽管它不能在每次运行中保持方差,但它可以使用超参数调整来保持每个类之间的距离。
该算法涉及大量的计算和计算。因此,该算法需要大量的时间和空间来计算。
复杂度是控制数据点拟合到算法中的主要参数。建议范围为(5–50)。
困惑应始终小于数据点的数量。
低困惑度→ 关注本地结构并关注最近的数据点。
高度困惑→ 关注全球结构。
t-SNE可以智能地处理离群值。
结论:
t-SNE是一种先进的降维技术。与PCA不同,t-SNE可以应用于线性和非线性良好聚类数据集,并更好地工作,产生更有意义的聚类。虽然t-SNE在可视化良好分离的聚类方面非常出色,但大多数时候它无法保留数据的全局几何结构。
如果您想进一步学习数据分析和挖掘领域的核心技术,推荐您参加中培IT学院的大数据挖掘、可视化与ChatGPT职场赋能培训课程,课程中针对大数据挖掘领域的方法、技术、原理进行深入透彻的讲解,可以有效为学员在数据分析实战领域赋能。
[1] |




