
随着ChatGPT的热度攀升,AI大模型越来越受到人们的关注。AI大模型指的是大型语言模型(LLM),其是一种人工智能(AI)算法,它使用深度学习技术和大规模数据集来理解、总结、生成和预测新内容。术语生成AI也与LLM密切相关,LLM实际上是一种生成AI,其专门构建用于帮助生成基于文本的内容。
AI大模型的诞生

几千年来,人类发展了口语来交流。语言是一切形式的人类和技术交流的核心;它提供了传达思想和概念所需的单词、语义和语法。在人工智能世界中,语言模型也有类似的用途,为交流和生成新概念提供了基础。
第一个人工智能语言模型可以追溯到人工智能的早期。伊莱扎语言模型于1966年在麻省理工学院首次亮相,是人工智能语言模式的最早例子之一。所有的语言模型首先在一组数据上训练,然后它们利用各种技术来推断关系,然后基于训练的数据生成新的内容。语言模型通常用于自然语言处理(NLP)应用程序,其中用户以自然语言输入查询以生成结果。
LLM是人工智能中语言模型概念的发展,它极大地扩展了用于训练和推理的数据。反过来,它极大地提高了人工智能模型的能力。虽然没有一个普遍接受的数字来表示训练数据集需要多大,但LLM通常具有至少10亿个或更多的参数。参数是一个机器学习术语,用于训练模型中存在的变量,这些变量可用于推断新内容。
现代LLM出现于2017年,使用变压器模型,这是通常称为变压器的神经网络。由于具有大量的参数和变压器模型,LLM能够快速理解和生成准确的响应,这使得人工智能技术广泛适用于许多不同的领域。
一些LLM被称为基础模型,这是斯坦福大学以人为中心的人工智能研究所(Stanford Institute for Human-Centered Artificial Intelligence)于2021年创造的一个术语。基础模型是如此庞大和有效,以至于它可以作为进一步优化和特定用例的基础。
为什么LLM对企业越来越重要?
随着人工智能的不断发展,它在商业环境中的地位变得越来越主导。这通过使用LLM和机器学习工具来体现。在构建和应用机器学习模型的过程中,研究建议,简单性和一致性应该是主要目标之一。确定必须解决的问题也很重要,理解历史数据并确保准确性也是如此。
与机器学习相关的好处通常分为四类:效率、有效性、经验和业务发展。随着这些技术的不断出现,企业对这项技术进行了投资。
大型语言模型是如何工作的?
LLM采用涉及多个组件的复杂方法:
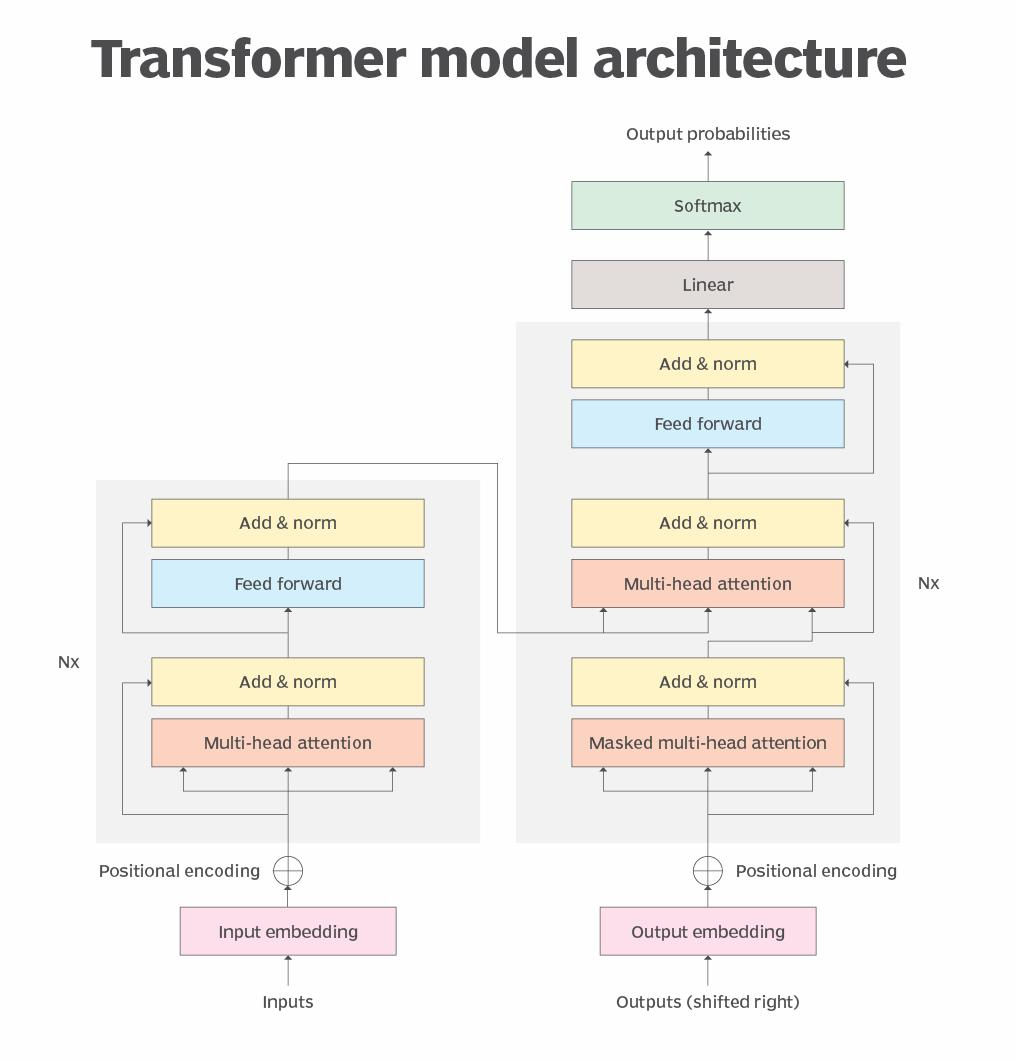
在基础层,LLM需要在通常为PB大小的大容量数据(有时称为语料库)上进行训练。培训可以采取多个步骤,通常从无监督学习方法开始。在该方法中,模型是在非结构化数据和未标记数据上训练的。关于未标记数据的培训的好处是,通常有更多的数据可用。在此阶段,模型开始推导不同单词和概念之间的关系。
一些LLM的下一步是使用自监督学习的形式进行训练和微调。在这里,发生了一些数据标记,帮助模型更准确地识别不同的概念。
接下来,LLM在通过变压器神经网络过程时进行深度学习。变压器模型架构使LLM能够使用自我注意机制来理解和识别单词和概念之间的关系和连接。该机制能够将分数(通常称为权重)分配给给定的项(称为令牌),以确定关系。
一旦训练了LLM,就存在一个基础,可以将AI用于实际目的。通过在提示下查询LLM,AI模型推理可以生成响应,响应可以是问题的答案、新生成的文本、摘要文本或情感分析报告。
大型语言模型的优势是什么?
LLM为组织和用户提供了许多优势:
可扩展性和适应性:LLM可以作为定制用例的基础。在LLM之上的额外培训可以为组织的特定需求创建一个微调的模型。
灵活性:一个LLM可以用于跨组织、用户和应用程序的许多不同任务和部署。
性能:现代LLM通常是高性能的,具有生成快速、低延迟响应的能力。
准确性:随着LLM中参数数量和训练数据量的增加,变压器模型能够提供越来越高的精度水平。
易于训练:许多LLM都是根据未标记的数据进行训练的,这有助于加快训练过程。
大型语言模型的挑战和限制是什么?

虽然使用LLM有许多优势,但也存在一些挑战和限制:
开发成本:为了运行,LLM通常需要大量昂贵的图形处理单元硬件和大量数据集。
运营成本:在培训和开发阶段之后,为东道国组织运营LLM的成本可能非常高。
偏见:任何人工智能在未标记数据上训练的风险都是偏见,因为并不总是清楚已知的偏见是否已被消除。
可解释性:对于用户来说,解释LLM如何生成特定结果的能力并不容易或明显。
幻觉:当LLM提供不基于训练数据的不准确响应时,就会出现人工智能幻觉。
复杂性:现代LLM具有数十亿个参数,是异常复杂的技术,其故障排除可能特别复杂。
故障标识:恶意设计的提示导致LLM故障,称为故障令牌,是2022年以来新兴趋势的一部分。
大型语言模型的未来
下一代LLM不太可能是人工通用智能或任何意义上的有知觉,但它们将不断改进并变得“更聪明”。LLM还将继续在它们可以处理的业务应用程序方面进行扩展。他们跨不同上下文翻译内容的能力将进一步增强,可能会使具有不同技术专业知识水平的业务用户更容易使用它们。在提供归因和更好地解释给定结果是如何生成的方面,未来的LLM也可能比当前一代做得更好。
随着技术继续以有助于提高人类生产力的方式发展,LLM的未来仍然光明。为了更好地应用大型语言模型,掌握相关的技能将成为IT职场主流。我们需要AI大模型全栈工程师,这是一个综合技能集合,要求掌握自然语言处理、机器学习、深度学习和软件工程等知识的专业人员。
为了学习和应用AI大模型相关技能,我推荐大家参加中培IT学院的AI大模型全栈工程师实战课程。这门课程将教授学员如何使用大型语言模型,并结合实际项目进行实践。学员将学习如何训练、调优和部署这些模型,以及如何处理数据隐私和安全性等问题。
此外,该课程还将涵盖自然语言处理和机器学习的基础知识,帮助学员建立坚实的技术基础。通过参加这门课程,学员将具备成为AI大模型全栈工程师所需的技能和知识,从而在利用大型语言模型方面取得成功,欢迎您的咨询!
[1] |




